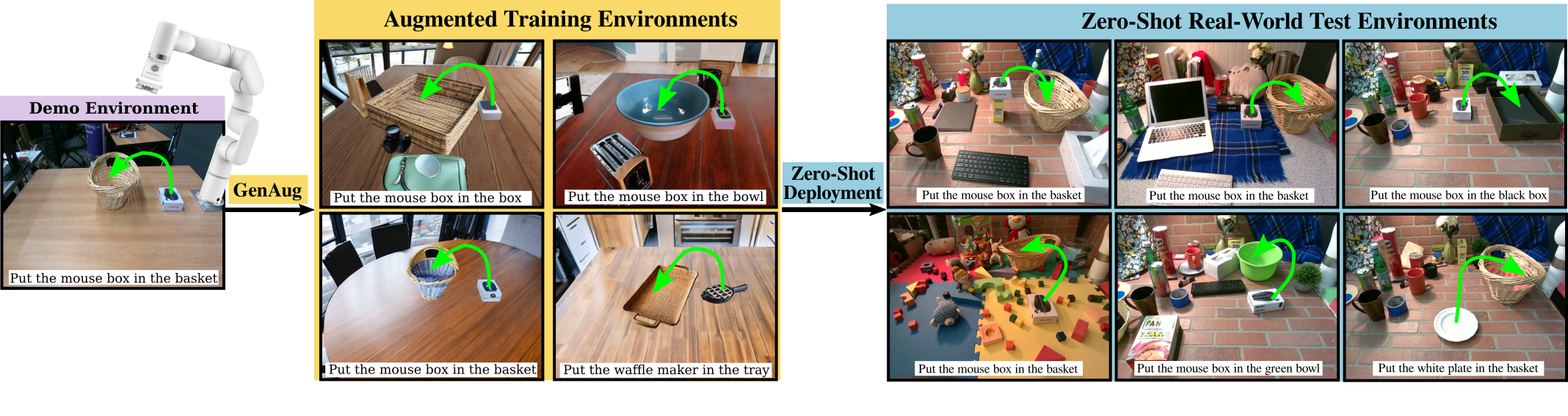
Simulation Experiments
To further study in depth the effectiveness of GenAug, we conduct large-scale experiments with other baselines in simulation.
In particular, we organize baseline methods as (1) in-domain augmentation methods and (2) learning from out-of-domain priors.
Table-top Manipulation Tasks


Behavior Cloning Tasks
In addition, we show GenAug can apply to Behavior Cloning tasks such as ”close the top drawer”, with a different robot:"Fetch".
In particular, we collected 100 demonstrations and trained a CNN-MLP behavior cloning policy finetuned with R3M embeddings.
The input is the RGB observation and the output is a 8-dim action vector.
We tested on 100 unseen backgrounds using iGibson rooms and observed GenAug is able to achieve 60% success rate
while policy without Genaug is only 1%, leading to almost 60% improvement.